RL and Truthfulness – Towards TruthGPT
本文為 RL and Truthfulness – Towards TruthGPT 的演講重點摘要
講者為 John Schulman (ChatGPT architect, OpenAI co-founder)
演講影片回播參考
Description
Goal
- 避免 model 出現’幻覺’(hallucination) → RLHF & Retrieval
- 講述自身對於 LLM 的宏觀的看法
Topic
模型為何會產生幻覺?
- 原理
- model 訓練時是以 pattern completion (給出完整答案) 的方式來進行, 這種機制會有
- 對於不確定的句子, 沒有回答’不知道’的常識
- 對於前提假設, 不會否決 (認為是統計分布的一部分)
- 回答出錯誤的資訊, 甚至是進一步的錯誤
- 第一次嘗試, 並且猜測錯誤
- model 訓練時是以 pattern completion (給出完整答案) 的方式來進行, 這種機制會有
- 簡易概念
- Pre-training model 好比是知識圖譜中的所有節點知識 (node)
- Fine tuning 就是將節點間的知識作融合 (link)
- behavior cloning: 透過監督學習的方式微調模型的目的就是要對給定的 prompt 最大化 maximum log likelihood
- 最大的問題: network 到底學會了那些知識, 這對於後續標註和實驗人員是未知的
- 透過 behavior cloning 的概念來訓練 model, 如果是不在知識圖譜 node 範圍內的知識, 等於在變相的教 model 產生幻覺
- 這點在 LLaMA 系列衍生的 model 可以發現這件事情
- 另一個方面, 如果在 behavior cloning 時, 去教 model 可以回答不知道, 某種狀況下等於在教 model 隱瞞事實

- 透過 behavior cloning 的概念來訓練 model, 如果是不在知識圖譜 node 範圍內的知識, 等於在變相的教 model 產生幻覺
- 如何預防?
- Model 知不知道自己在唬爛?
- 知道, 對於給定的 prompt 下下個字都會有機率分布
- 可以讓 model 表達這些不確定性, 並給出與輸出機率值類似的結果 (參考 paper: Language Models (Mostly) Know What They Know)
- John Schulman 認為強化學習是解決幻覺的正解, 但對於 behavior cloning 還是有些小技巧可以嘗試
- 訓練時告訴模型 (1) ‘我不知道’ (2) ‘我的知識節止於 xx 日期’ (3) 質疑提問的範例
- 強化學習如何解決幻覺?
- 訓練 model 的邊界, 這個邊界類似於信心程度 (很有信心的正確答案, 模糊的正確答案, 不知道, 模糊的錯誤答案, 完全錯誤的答案)
- 為了達到這目標不是一個容易的事, 因為需要知道答案是否正確
- Model 知不知道自己在唬爛?
- 小實驗
- TriviaQA 是一個流行的問答數據集, 包含了一系列的嘗試問題 (相關資料)
- 實驗設定是每筆資料都有一個答案, 訓練時都會進行 behavior cloning, 所以都會輸出一個答案 (只有錯誤和正確)
- 這種監督式學習的方式使用少量數據就能夠達到一定的準確度, 實際上這種方式只是教 model 試圖輸出正確答案, 而沒有交模型太多新的知識, 更多的是回答問題的格式和處理方式
- 個人觀點: 可以把強化學習當作是學習說話的策略(輸出 threshold), 對於不確定的答案更傾向回答不知道藉此獲得更小的 loss

標註的難題
- 怎麼標註長文本?
- 長文本往往發生讓回答處於一種灰色地帶, 部分真實以及部分錯誤, 這種問題對於標註員是一個很困難的問題(也許連標註員都不知道哪部分錯誤)
- 由於沒有完美的答案, 因此標註的做法轉為去比較各種回答, 對所有的答案進行排序
- 如何 align model & 標註員認知的正確答案?
新知識注入
- 動機: 如何引入不在預訓練資料中的訊息(最新事件、私人訊息、聊天紀錄)
- 如何驗證 model 在唬爛?
- 人為檢查的依據(來源 & 引用)
- 應用 - WebGPT
- 藉由獲取網路的最新資料, 讓 model 參考資料後得出答案並列出來源
- webGPT 是使用 GPT3 的 model, 對於最新的 GPT3.5 or GPT4 也許不需要做查詢就能回答出正確答案
- 由於 model 的文本長度有限制 (4000 個 token), 能夠餵入的參考文章是有限的, 所以透過引用的方式可以保留參考文章訊息並且刪除這些上下文 (???)
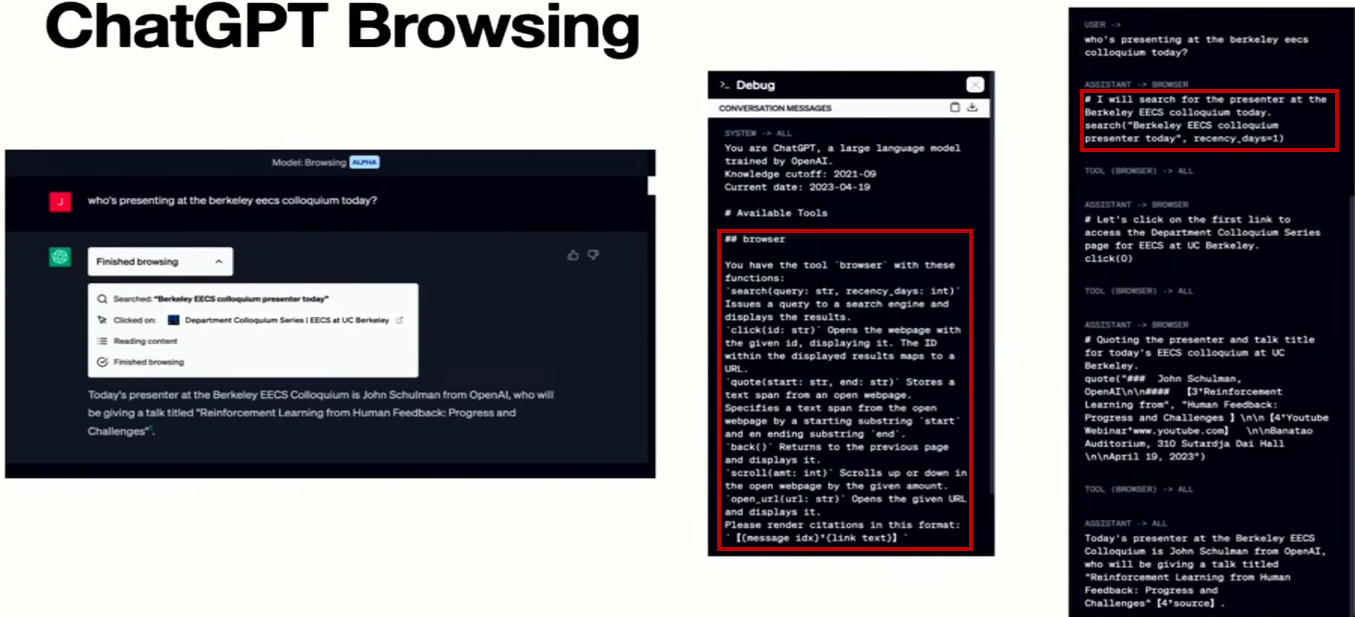
- 應用 - ChatGPT plugin
- 類似 toolformer 的想法, 詳細的跟 model 說有那些工具 & 接口, 模型會進行相應的操作並產生出’內心獨白’
- ChatGPT 只有在不知道答案的情況下去使用瀏覽模式
Conclusion
- 這篇演講的解釋了 LLM '可能’的運作模式, 以及現在主流的方案存在那些本質上的問題
- 對於 close domain 領域的資料, 短期內不會有太多新的技術可以考慮 pre-training 讓 model 可以完整地看過所有資料在進行 instruction tuning
- 對於 open domain 領域的資料, 短期內會有大量新知識可以考慮使用 retrieval 的方式來外掛知識
- OpenAI 在解決 model 產生的幻覺 issue 上, 花了很大的 effort, 在最新的 paper (Let’s Verify Step by Step) 也提出了’過程監督’的方法, 讓 model 在訓練過程中把幻覺自動抓出來